网站索引:检查与修复指南

什么是网站索引?
搜索引擎索引(简称“索引”)是将网页存储在数据库中的过程。只有被索引的网页才能出现在搜索结果中。这是搜索引擎优化 (SEO) 的基础——未被索引的网页不会获得排名或任何自然搜索流量。许多客户网站长期以来都没有任何排名或自然搜索流量,无论原因如何,基本上只有首页和少数几个页面被索引。通过分析客户的 Google Search Console 覆盖率报告,常见的索引障碍包括:
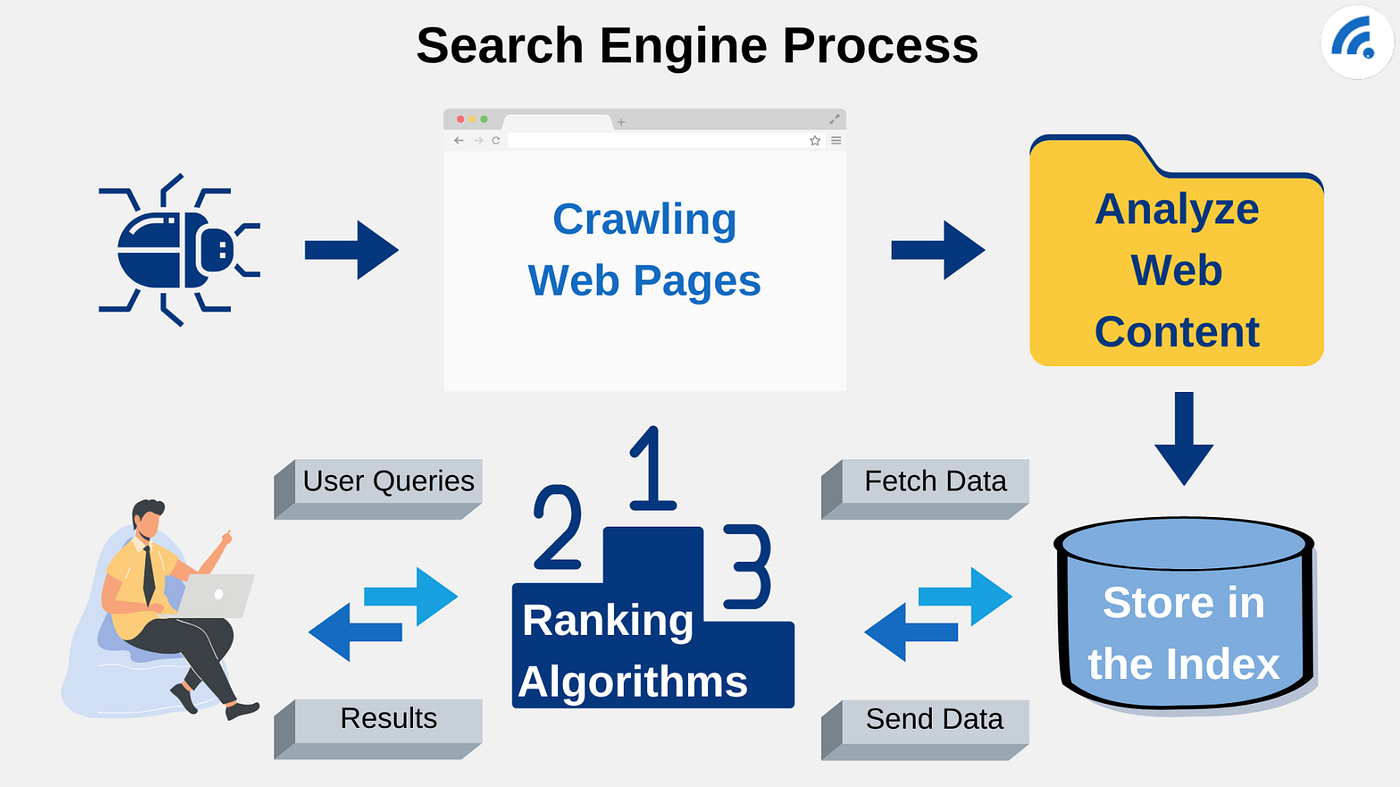
此图展示了搜索引擎抓取、索引和排名的过程。
需要检查和确保的内容:网站已被索引(通常在提交到 Google Search Console 后 2-3 天内完成,这不是什么大问题),重要页面已被索引(需要定期检查,建议至少每月使用 site 命令或查看 Google Search Console 检查一次)。
常见的索引障碍比例:
•页面质量得分不足(12%)
•robots.txt 误拦截(28% 的非索引案例)
•重复内容导致的规范问题(22%)
•服务器响应异常(例如 5xx 错误,占 17%)
检查网站索引状态
检查索引的方法
Google 命令检查:在 Google 搜索栏中输入“site:yourdomain.com”(不带引号)。此命令将显示当前已索引页面的列表。
Google Search Console 检查:登录 Google Search Console,转到左侧导航栏中的“网页”报告。
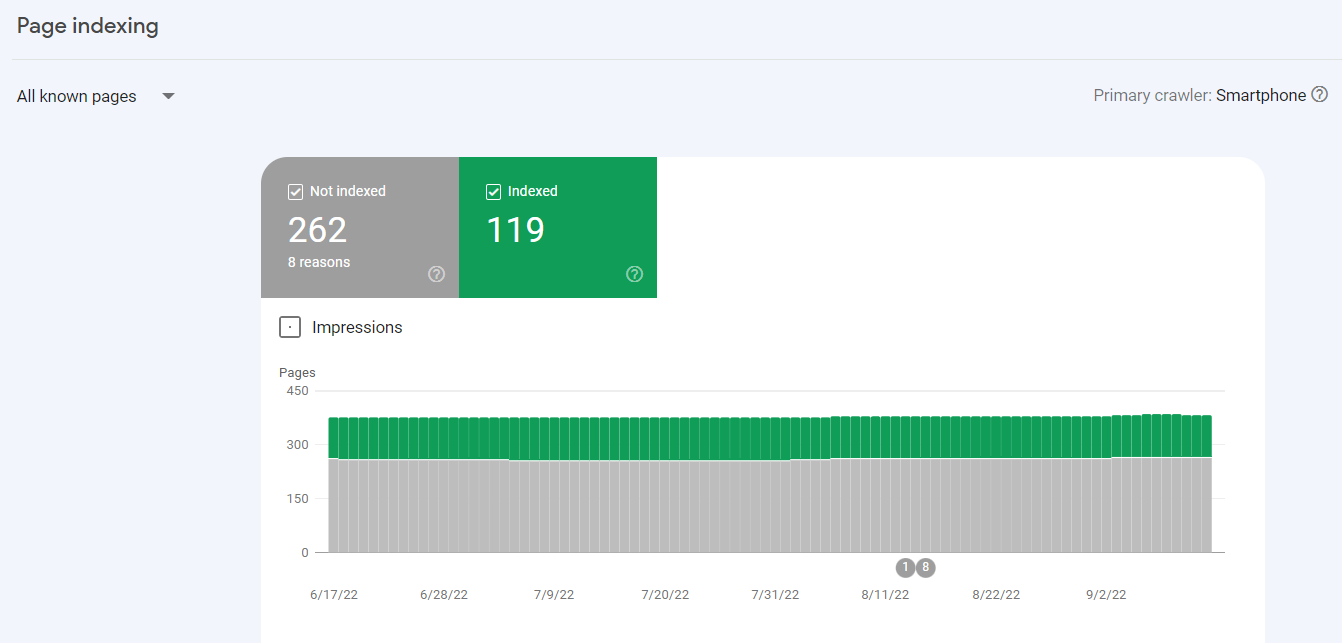
Google Search Console 页面索引报告,显示已索引和未索引页面的数量及历史趋势图。
如何绑定和查看 Google Search Console,请阅读本文:如何将您的网站提交给搜索引擎
网页被谷歌收录的过程主要包括三个步骤:抓取、索引和排名。确保搜索引擎能够理解并展示网页内容。通过提交网站管理员工具、验证网站所有权以及优化网站结构,您可以提高网页抓取和索引速度,从而提升搜索引擎排名。
第三方工具检查:使用 AITDK 等插件。
验证索引计数
Google 搜索命令和 AITDK 显示索引数量为 34,而 GSC 显示索引数量为 26。实际网站页面数为 33,大致相符即可。如果您不清楚实际页面数,可以查看站点地图或借助第三方工具查看。这对于中大型网站尤为重要,特别是要确保关键版块或页面已被索引。您还可以通过两种方法逐一分析不同的二级版块。
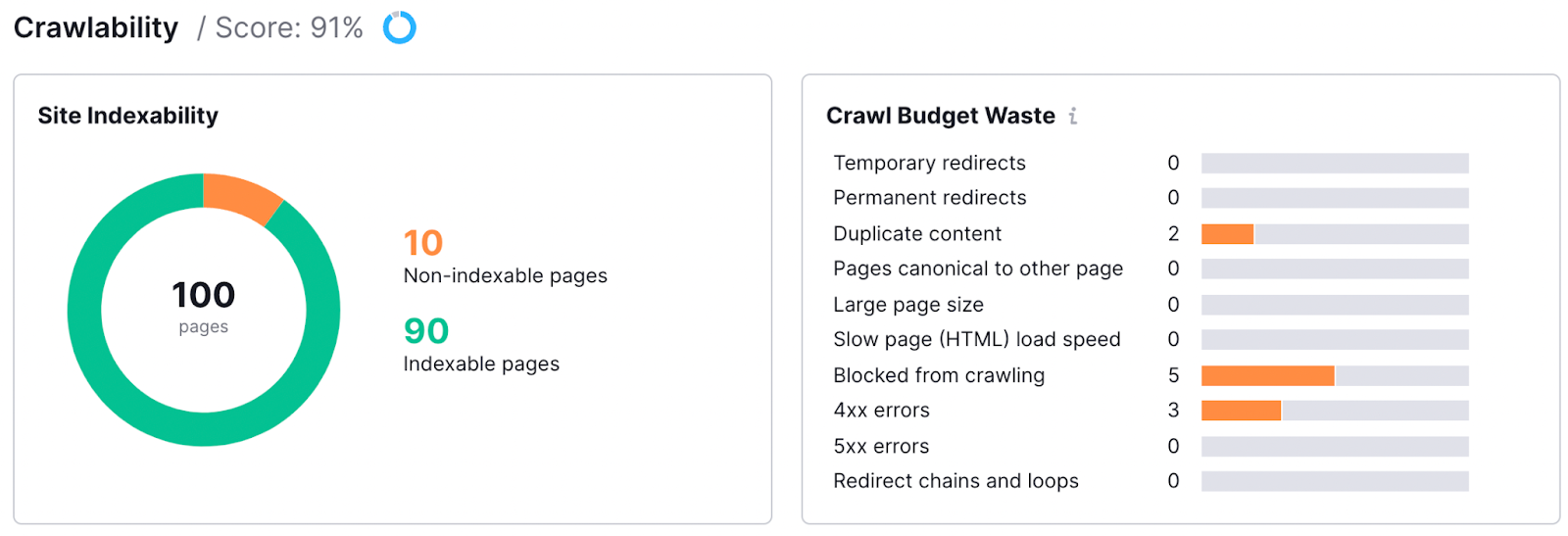
Semrush 网站审计仪表盘,显示抓取和索引指标,包括可索引和不可索引页面。
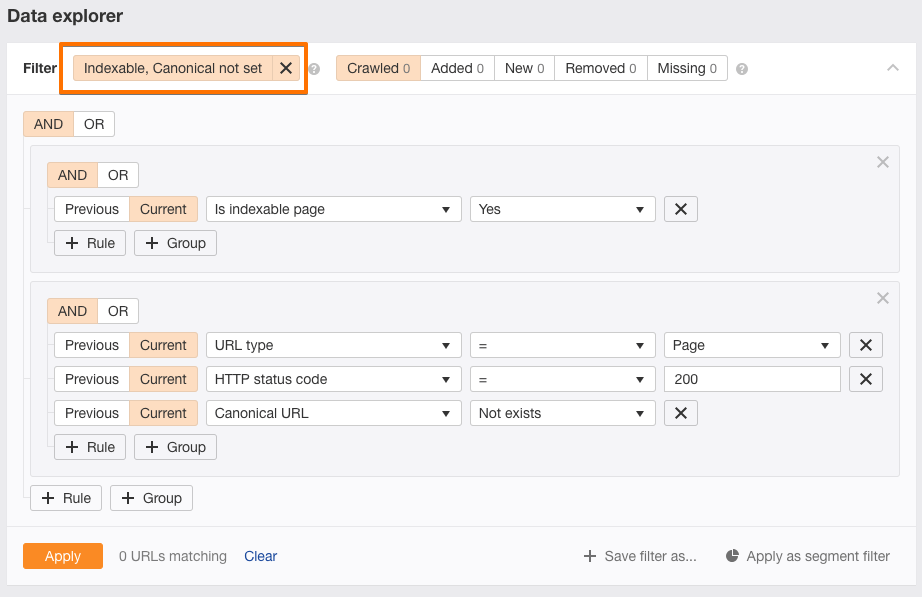
Ahrefs 网站审计数据浏览器截图,显示索引性和规范问题的筛选器。
对网站索引问题进行分类和修复
在搜索引擎优化系统中,索引失败通常源于技术和策略层面的复合问题。根据谷歌官方索引覆盖率报告的统计数据,超过 80% 的网站至少存在三种未被发现的索引障碍。这些“隐形漏斗”可能导致内容有效丢失。我结合谷歌官方手册和自身经验,整理了一条从服务器响应到页面级指令的完整故障链。
确定主要问题是什么
通常只有技术问题才会导致大量页面在短时间内无法被索引(使用人工智能批量发布低质量页面属于内容问题)。
服务器响应异常(5xx 错误)
当搜索引擎请求网页时,服务器会返回 500 级别的错误代码(例如 502 Bad Gateway、503 Service Unavailable 等),表明服务器端存在临时或持续性故障。这些错误会直接阻止爬虫抓取网页内容,需要通过服务器日志分析并结合相关工具(例如 Google Search Console 的覆盖率报告)来定位。

此图展示了 404 和 503 服务器错误,适用于解释 HTTP 状态码的 SEO 博客文章。
重定向配置异常
包括以下四个常见问题:
•重定向链过长(超过 3 次跳跃)
•重定向循环(A→B→A 死循环)
•最终重定向 URL 超过字符限制(超过 2,048 字节)
•重定向路径中的 URL 无效或为空
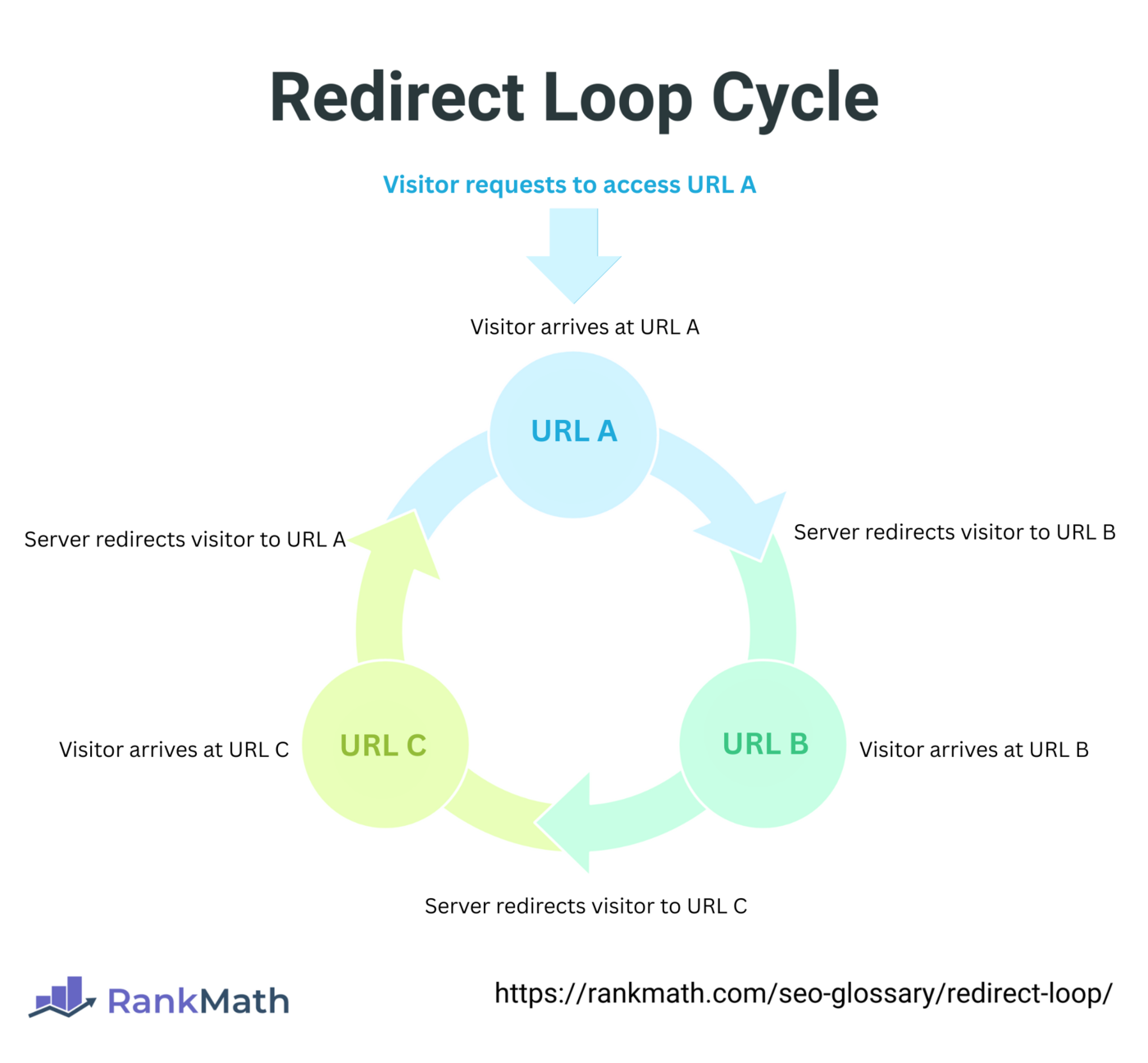
此图展示了一个重定向循环,访问者从 URL A 重定向到 B,再到 C,最后又回到 A,形成无限循环。
robots.txt 拦截风险
当网站根目录下的 robots.txt 文件中的 Disallow 指令屏蔽了某些页面时,搜索引擎将不会主动抓取这些页面。但是请注意:如果这些页面被其他网站链接或存在于已提交的 XML Sitemap 中,则仍有可能被搜索引擎索引。要彻底禁止索引,您需要同时移除 robots.txt 文件中的限制并添加“noindex”元标签。
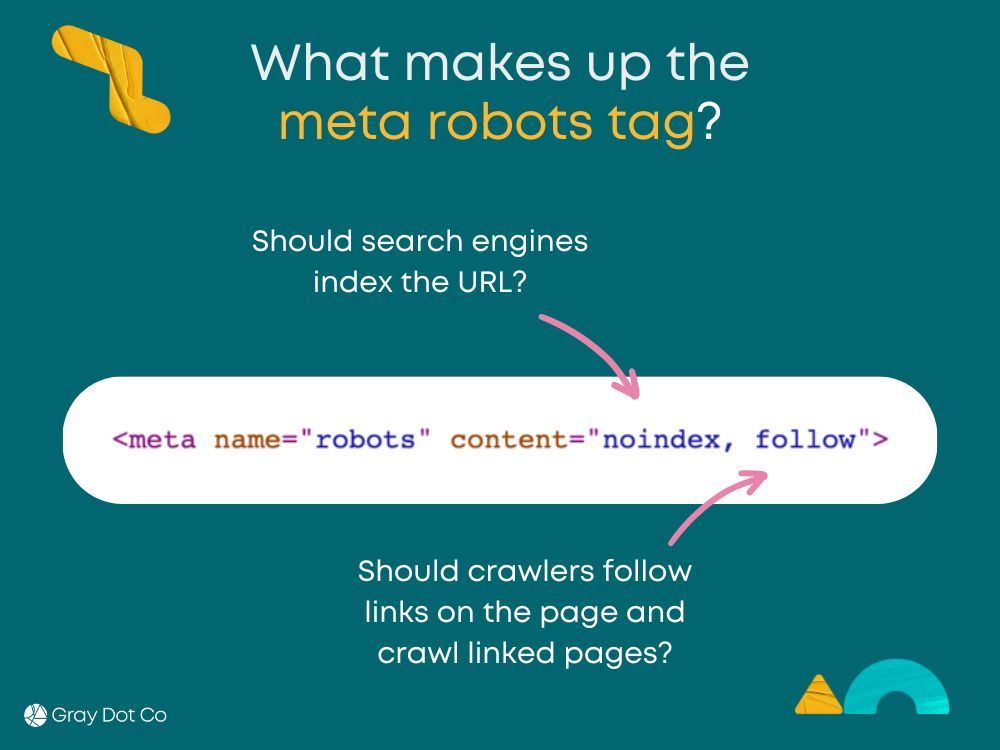
此图解释了 meta robots 标签的组成部分,特别是 noindex, follow 指令。
主动索引阻止(Noindex 指令)
页面源代码中的 <meta name="robots" content="noindex"> 标签或 HTTP 响应头中的 X-Robots-Tag 指令会明确告知搜索引擎不要索引该页面。在 Google Search Console 的网址检查工具中,“允许索引”状态将显示为“已被 noindex 阻止”。您需要通过实时测试来确认该指令是否已被移除。
软性 404 页
页面显示“未找到”提示,但不返回标准的 404 HTTP 状态码,导致搜索引擎误判页面有效性。这种情况常见于内容被删除但未配置正确的响应代码,或者自定义错误页面不符合技术规范。
权限验证被阻止(401/403 错误)
401 错误需要身份验证,而 Googlebot 不会提供凭据(爬虫无法像真实用户一样登录)。403 错误表示服务器配置错误,导致合法请求被拒绝。解决方案包括:移除页面访问限制、设置爬虫白名单(需要 Search Console 所有权验证)或配置免身份验证访问路径。
已抓取但未索引
页面状态分为两种:“已抓取 - 当前未索引”和“已发现 - 当前未索引”。前者可能是由于页面质量评估尚未达到标准,而后者通常是由服务器负载保护机制导致的抓取延迟触发。这部分与技术问题无关,也是最常见的问题。前者是因为您的页面质量太低,即使您强制提交索引,一段时间后也会被标记为“未索引”。后者是因为您发布页面的速度过快,导致抓取配额不足。通常,这两种情况的出现是因为您(使用人工智能)通过程序生成低质量页面。这两种问题也最容易受到谷歌的惩罚。
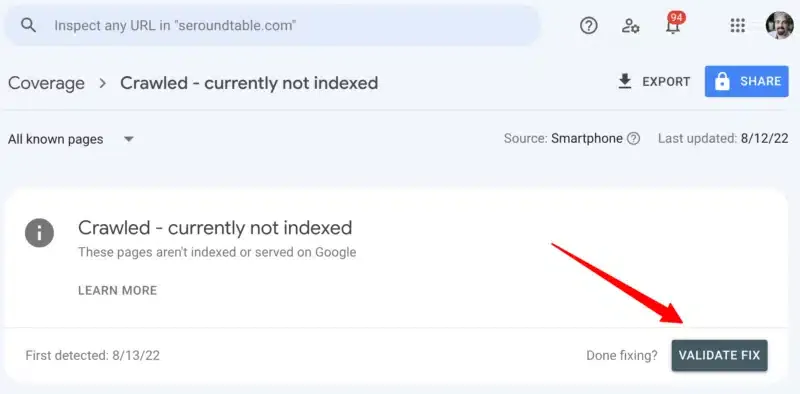
Google Search Console 截图,显示“已抓取 - 当前未索引”状态和“验证修复”按钮。
合理的非指数化情景
并非所有页面都需要被索引(只有需要进行 SEO 优化的页面才应该出现在谷歌搜索结果中)。有些页面甚至需要从索引中排除,例如仅用于用户交互的应用/仪表盘子域名、开发/测试环境、条款/政策子目录等也不需要显示。
此外,以下类型的页面也不需要强制索引:
•重定向页面(301/302,因为目标页面已被索引)
•后端管理系统接口
•重复的内容页面已设置规范标签(因为规范页面已被索引)
•RSS 订阅页面(带有/feed的页面)
规范版本识别冲突和重定向
包括三种典型场景:
•页面正确声明了规范版本,但未被索引(备用页面)
•未声明规范页面,导致搜索引擎自行选择(重复页面,无规范页面)
•已声明的规范页面与搜索引擎的判断相冲突(规范冲突)
默认情况下,重定向 URL 不会被索引为独立页面,但如果规范页面本身有重定向(例如 A→B 且 A 被声明为规范页面),则可能会导致索引逻辑混乱。
修复流程
如果您发现重要页面未被索引:
•根据提示修复技术问题(例如删除错误的 noindex 标签)
•点击“验证修复”按钮以触发人工审核
•监控“覆盖范围报告”的更新状态(通常需要 3-7 个工作日)
工具
•Google 官方索引问题文档:谷歌官方文档列出了所有未被收录的原因和解决方案,但实际上,这仍然很大程度上依赖于 SEO 经验。
•Semrush 网站审核工具:Semrush 网站审核可以检测索引问题。
•Ahrefs 索引性工具:Ahrefs Indexability 还可以检测索引问题。